
PostgreSQL - PostgreSQL
![Самая продвинутая в мире реляционная база данных с открытым исходным кодом [1]](https://wikipedia.org/wiki/File:Postgresql_elephant.svg) Самая продвинутая в мире реляционная база данных с открытым исходным кодом
| |
| Разработчики) | Группа глобального развития PostgreSQL |
|---|---|
| Первый выпуск | 8 июля 1996 г . |
| Стабильный выпуск | 14.0 |
| Репозиторий | |
| Написано в | C |
| Операционная система | macOS , Windows , Linux , FreeBSD , OpenBSD |
| Тип | СУБД |
| Лицензия | Лицензия PostgreSQL ( бесплатно и с открытым исходным кодом , разрешающая ) |
| Веб-сайт |
www |
| Издатель | Группа глобального развития PostgreSQL Регенты Калифорнийского университета |
|---|---|
| Совместимость с Debian FSG | да |
| ФСПО утверждено | да |
| OSI одобрено | да |
| GPL совместимый | да |
| Авторское лево | Нет |
| Связывание из кода с другой лицензией | да |
| Веб-сайт | postgresql |
PostgreSQL ( / р oʊ с т ɡ г ɛ с ˌ к Ju ɛ л / , POHST -gres Kyoo эль ), также известный как Postgres , является свободным и открытым исходным кодом управления реляционной базой данных системы (СУБД) подчеркивает расширяемость и SQL соответствие . Первоначально он назывался POSTGRES, имея в виду его происхождение как преемника базы данных Ingres, разработанной в Калифорнийском университете в Беркли . В 1996 году проект был переименован в PostgreSQL, чтобы отразить поддержку SQL . После обзора в 2007 году команда разработчиков решила сохранить имя PostgreSQL и псевдоним Postgres.
PostgreSQL предлагает транзакции со свойствами атомарности, согласованности, изоляции, долговечности (ACID), автоматически обновляемые представления , материализованные представления , триггеры , внешние ключи и хранимые процедуры . Он предназначен для обработки ряда рабочих нагрузок, от отдельных компьютеров до хранилищ данных или веб-сервисов с множеством одновременных пользователей . Это база данных по умолчанию для macOS Server, она также доступна для Windows , Linux , FreeBSD и OpenBSD .
История
PostgreSQL произошел от проекта Ingres в Калифорнийском университете в Беркли. В 1982 году лидер команды Ingres Майкл Стоунбрейкер покинул Беркли, чтобы создать собственную версию Ingres. Он вернулся в Беркли в 1985 году и начал пост-Ingres проект по решению проблем с современными системами баз данных, которые стали все более очевидными в начале 1980-х годов. В 2014 году он получил премию Тьюринга за эти и другие проекты и впервые примененные в них методы.
Новый проект POSTGRES был направлен на добавление минимального количества функций, необходимых для полной поддержки типов данных . Эти функции включали возможность определять типы и полностью описывать отношения - что-то широко используемое, но полностью поддерживаемое пользователем. В POSTGRES база данных понимала отношения и могла извлекать информацию из связанных таблиц естественным образом, используя правила . ПОСТГРЭС использовал многие идеи Энгра, но не его код.
Начиная с 1986 года в опубликованных статьях описывалась основа системы, а прототип был показан на конференции ACM SIGMOD 1988 года . Команда выпустила версию 1 для небольшого числа пользователей в июне 1989 года, а затем версию 2 с переписанной системой правил в июне 1990 года. Версия 3, выпущенная в 1991 году, снова переписала систему правил и добавила поддержку нескольких менеджеры хранения и улучшенный механизм запросов. К 1993 году количество пользователей начало заваливать проект просьбами о поддержке и функциях. После выпуска версии 4.2 30 июня 1994 года - в первую очередь очистки - проект завершился. Беркли выпустил POSTGRES в соответствии с вариантом лицензии MIT , что позволило другим разработчикам использовать код для любого использования. В то время POSTGRES использовал интерпретатор языка запросов POSTQUEL под влиянием Ingres , который можно было интерактивно использовать с консольным приложением с именем monitor.
В 1994 году аспиранты Беркли Эндрю Ю и Джолли Чен заменили интерпретатор языка запросов POSTQUEL на интерпретатор для языка запросов SQL, создав Postgres95. monitorКонсоль была также заменена psql. Ю и Чен объявили бета-тестерам первую версию (0.01) 5 мая 1995 года. Версия 1.0 Postgres95 была анонсирована 5 сентября 1995 года с более либеральной лицензией, которая позволяла свободно изменять программное обеспечение.
8 июля 1996 года Марк Фурнье из Hub.org Networking Services предоставил первый неуниверситетский сервер разработки для разработки с открытым исходным кодом. При участии Брюса Момджяна и Вадима Б. Михеева началась работа по стабилизации кода, унаследованного от Беркли.
В 1996 году проект был переименован в PostgreSQL, чтобы отразить поддержку SQL. Онлайн-присутствие на веб-сайте PostgreSQL.org началось 22 октября 1996 года. Первый выпуск PostgreSQL образовал версию 6.0 29 января 1997 года. С тех пор разработчики и добровольцы по всему миру поддерживали программное обеспечение как The PostgreSQL Global Development Group.
В рамках проекта выпуски выпусков по-прежнему доступны на условиях лицензии PostgreSQL на бесплатное программное обеспечение с открытым исходным кодом . Код поступает от поставщиков проприетарных решений, компаний поддержки и программистов с открытым исходным кодом.
Управление многоверсионным параллелизмом (MVCC)
PostgreSQL управляет параллелизмом посредством управления многоверсионным параллелизмом (MVCC), который дает каждой транзакции «моментальный снимок» базы данных, позволяя вносить изменения, не затрагивая другие транзакции. Это в значительной степени устраняет необходимость в блокировках чтения и гарантирует, что база данных поддерживает принципы ACID . PostgreSQL предлагает три уровня изоляции транзакций : зафиксированные на чтение, повторяющееся чтение и сериализуемые. Поскольку PostgreSQL невосприимчив к грязному чтению, запрос уровня изоляции транзакции Read Uncommitted вместо этого обеспечивает фиксацию чтения. PostgreSQL поддерживает полную сериализуемость с помощью метода изоляции сериализуемых моментальных снимков (SSI).
Хранение и репликация
Репликация
PostgreSQL включает встроенную двоичную репликацию, основанную на асинхронной доставке изменений ( журналы упреждающей записи (WAL)) на реплики узлов с возможностью выполнения запросов только для чтения к этим реплицированным узлам. Это позволяет эффективно распределять трафик чтения между несколькими узлами. Более раннее программное обеспечение репликации, которое позволяло аналогичное масштабирование чтения, обычно полагалось на добавление триггеров репликации к главному устройству, что увеличивало нагрузку.
PostgreSQL включает встроенную синхронную репликацию, которая гарантирует, что для каждой транзакции записи мастер ждет, пока хотя бы один узел реплики не запишет данные в свой журнал транзакций. В отличие от других систем баз данных, надежность транзакции (асинхронной или синхронной) может быть указана для каждой базы данных, пользователя, сеанса или даже транзакции. Это может быть полезно для рабочих нагрузок, которые не требуют таких гарантий, и может не требоваться для всех данных, поскольку снижает производительность из-за требования подтверждения транзакции, достигающей синхронного резервного.
Резервные серверы могут быть синхронными или асинхронными. Синхронные резервные серверы могут быть указаны в конфигурации, которая определяет, какие серверы являются кандидатами для синхронной репликации. Первый в списке активный потоковый сервер будет использоваться в качестве текущего синхронного сервера. Когда это не удается, система переключается на следующую в очереди.
Синхронная репликация с несколькими мастерами не включена в ядро PostgreSQL. Postgres-XC, основанный на PostgreSQL, обеспечивает масштабируемую синхронную репликацию с несколькими мастерами. Он находится под той же лицензией, что и PostgreSQL. Связанный проект называется Postgres-XL . Postgres-R - еще один форк . Двунаправленная репликация (BDR) - это система асинхронной репликации с несколькими мастерами для PostgreSQL.
Такие инструменты, как repmgr, упрощают управление кластерами репликации.
Доступно несколько пакетов асинхронной репликации на основе триггеров. Они остаются полезными даже после введения расширенных возможностей ядра в ситуациях, когда двоичная репликация всего кластера базы данных неуместна:
- Slony-I
- Лондист, часть SkyTools (разработка Skype )
- Bucardo multi-master replication (разработано Backcountry.com )
- SymmetricDS с несколькими мастерами, многоуровневая репликация
YugabyteDB - это база данных, которая использует внешний интерфейс PostgreSQL с серверной частью, более похожей на NoSQL . Хотя ее можно рассматривать как другую базу данных, по сути, это PostgreSQL с другим сервером хранения. Он решает проблемы репликации с реализацией идей от Google Spanner . Такие базы данных называются NewSQL и включают , среди прочего, CockroachDB и TiDB .
Индексы
PostgreSQL включает встроенную поддержку индексов обычных B-деревьев и хэш-таблиц , а также четыре метода доступа к индексам: обобщенные деревья поиска ( GiST ), обобщенные инвертированные индексы (GIN), GiST с разделением по пространству (SP-GiST) и индексы диапазонов блоков ( БРИН). Кроме того, могут быть созданы определяемые пользователем методы индексации, хотя это довольно сложный процесс. Индексы в PostgreSQL также поддерживают следующие функции:
- Индексы выражения могут быть созданы с помощью индекса результата выражения или функции, а не просто значения столбца.
- Частичные индексы , которые индексируют только часть таблицы, можно создать, добавив предложение WHERE в конец оператора CREATE INDEX. Это позволяет создать меньший индекс.
- Планировщик может использовать несколько индексов вместе для удовлетворения сложных запросов, используя операции с временными индексами растровых изображений в памяти (полезно для приложений хранилища данных для присоединения большой таблицы фактов к меньшим таблицам измерений, например, расположенным в звездообразной схеме ).
- Индексирование k- ближайших соседей ( k -NN) (также называемое KNN-GiST) обеспечивает эффективный поиск «ближайших значений» к заданному, полезно для поиска похожих слов или близких объектов или местоположений с геопространственными данными. Это достигается без исчерпывающего сопоставления значений.
- Сканирование только по индексу часто позволяет системе извлекать данные из индексов, даже не обращаясь к основной таблице.
- Индексы диапазонов блоков (BRIN).
Схемы
В PostgreSQL схема содержит все объекты, кроме ролей и табличных пространств. Схемы эффективно действуют как пространства имен, позволяя объектам с одинаковыми именами сосуществовать в одной базе данных. По умолчанию вновь созданные базы данных имеют схему, называемую общедоступной , но могут быть добавлены любые дополнительные схемы, и общедоступная схема не является обязательной.
search_pathПараметр определяет порядок , в котором PostgreSQL проверяет схемы для неквалифицированных объектов (те без приставки схемы). По умолчанию он установлен в $user, public( $userотносится к текущему подключенному пользователю базы данных). Это значение по умолчанию может быть установлено на уровне базы данных или роли, но, поскольку это параметр сеанса, его можно свободно изменять (даже несколько раз) во время сеанса клиента, влияя только на этот сеанс.
Несуществующие схемы, перечисленные в search_path, автоматически пропускаются во время поиска объектов.
Новые объекты создаются в зависимости от того, какая действующая схема (существующая в настоящее время) появляется первой в search_path.
Типы данных
Поддерживаются самые разные собственные типы данных , в том числе:
- Логический
- Произвольные точности Числовых
- Символ (текст, varchar, char)
- Двоичный
- Дата / время (отметка времени / время с / без часового пояса, даты, интервала)
- Деньги
- Enum
- Битовые строки
- Тип текстового поиска
- Композитный
- HStore, хранилище ключей и значений с расширением в PostgreSQL
- Массивы (переменной длины и могут относиться к любому типу данных, включая текстовые и составные) до 1 ГБ в общем объеме хранилища
- Геометрические примитивы
- IPv4 и IPv6 - адрес
- Блоки и MAC-адреса бесклассовой междоменной маршрутизации (CIDR)
- XML, поддерживающий запросы XPath
- Универсальный уникальный идентификатор (UUID)
- Нотация объектов JavaScript ( JSON ) и более быстрый двоичный JSONB (не то же самое, что BSON )
Кроме того, пользователи могут создавать свои собственные типы данных, которые обычно можно сделать полностью индексируемыми с помощью инфраструктур индексирования PostgreSQL - GiST, GIN, SP-GiST. Примеры включают типы данных географической информационной системы (ГИС) из проекта PostGIS для PostgreSQL.
Существует также тип данных, называемый доменом , который аналогичен любому другому типу данных, но с дополнительными ограничениями, определенными создателем этого домена. Это означает, что любые данные, введенные в столбец с использованием домена, должны соответствовать тем ограничениям, которые были определены как часть домена.
Можно использовать тип данных, который представляет диапазон данных, которые называются типами диапазона. Это могут быть дискретные диапазоны (например, все целые значения от 1 до 10) или непрерывные диапазоны (например, любое время между 10:00 и 11:00 ). Доступные встроенные типы диапазонов включают диапазоны целых чисел, большие целые числа, десятичные числа, отметки времени (с часовым поясом и без него) и даты.
Можно создать настраиваемые типы диапазонов, чтобы сделать доступными новые типы диапазонов, например диапазоны IP-адресов, использующие тип inet в качестве основы, или диапазоны с плавающей запятой, используя тип данных float в качестве основы. Типы диапазонов поддерживают включающие и исключающие границы диапазона с использованием символов [/ ]и (/ )соответственно. (например, [4,9)представляет все целые числа, начиная с 4 и заканчивая 9, но не включая 9.) Типы диапазонов также совместимы с существующими операторами, используемыми для проверки на перекрытие, включение, право на и т. д.
Пользовательские объекты
Можно создавать новые типы почти всех объектов внутри базы данных, в том числе:
- Броски
- Конверсии
- Типы данных
- Домены данных
- Функции, включая агрегатные функции и оконные функции
- Индексы, включая пользовательские индексы для пользовательских типов
- Операторы (существующие могут быть перегружены )
- Процедурные языки
Наследование
Таблицы можно настроить так, чтобы они наследовали свои характеристики от родительской таблицы. Данные в дочерние таблицы будут отображаться существовать в родительских таблиц, если данные не будут выбраны из родительской таблицы , используя только ключевое слово, то есть . Добавление столбца в родительскую таблицу приведет к тому, что этот столбец появится в дочерней таблице.
SELECT * FROM ONLY parent_table;
Наследование можно использовать для реализации разделения таблицы с использованием триггеров или правил для направления вставок из родительской таблицы в соответствующие дочерние таблицы.
По состоянию на 2010 год эта функция еще не полностью поддерживается - в частности, ограничения таблиц в настоящее время не наследуются. Все проверочные ограничения и ограничения, не равные NULL в родительской таблице, автоматически наследуются ее дочерними элементами. Другие типы ограничений (ограничения уникальности, первичного ключа и внешнего ключа) не наследуются.
Наследование обеспечивает способ сопоставления функций иерархий обобщения, изображенных на диаграммах отношений сущностей (ERD), непосредственно в базе данных PostgreSQL.
Другие особенности хранения
- Ссылочная целостность ограничение в том числе внешнего ключа ограничения, колонки ограничений и проверок строк
- Двоичное и текстовое хранилище больших объектов
- Табличные пространства
- Сортировка по столбцам
- Онлайн-резервное копирование
- Восстановление на определенный момент времени, реализованное с использованием ведения журнала с упреждающей записью
- Обновления на месте с помощью pg_upgrade для сокращения времени простоя
Контроль и связь
Обертки сторонних данных
PostgreSQL может связываться с другими системами для получения данных через оболочки сторонних данных (FDW). Они могут принимать форму любого источника данных, например файловой системы, другой системы управления реляционными базами данных (СУБД) или веб-службы. Это означает, что обычные запросы к базе данных могут использовать эти источники данных как обычные таблицы и даже объединять несколько источников данных вместе.
Интерфейсы
Для подключения к приложениям PostgreSQL включает встроенные интерфейсы libpq (официальный интерфейс приложения C) и ECPG (встроенная система C). Сторонние библиотеки для подключения к PostgreSQL доступны для многих языков программирования , включая C ++ , Java , Julia , Python , Node.js , Go и Rust .
Процедурные языки
Процедурные языки позволяют разработчикам расширять базу данных пользовательскими подпрограммами (функциями), часто называемыми хранимыми процедурами . Эти функции могут использоваться для создания триггеров базы данных (функций, вызываемых при изменении определенных данных), а также для пользовательских типов данных и агрегатных функций . Процедурные языки также можно вызывать без определения функции, используя команду DO на уровне SQL.
Языки разделены на две группы: Процедуры, написанные на безопасных языках, изолированы и могут быть безопасно созданы и использованы любым пользователем. Процедуры, написанные на небезопасных языках, могут быть созданы только суперпользователями , поскольку они позволяют обходить ограничения безопасности базы данных, но также могут обращаться к источникам, внешним по отношению к базе данных. Некоторые языки, такие как Perl, предоставляют как безопасные, так и небезопасные версии.
PostgreSQL имеет встроенную поддержку трех процедурных языков:
- Обычный SQL (безопасный). Более простые функции SQL могут быть расширены встроенными в вызывающий (SQL) запрос, что экономит накладные расходы на вызов функции и позволяет оптимизатору запросов «заглядывать внутрь» функции.
- Procedural Language / PostgreSQL ( PL / pgSQL ) (безопасный), который напоминает процедурный язык Oracle Procedural Language for SQL ( PL / SQL ) и SQL / Persistent Stored Modules ( SQL / PSM ).
- C (небезопасный), который позволяет загружать одну или несколько пользовательских разделяемых библиотек в базу данных. Функции, написанные на C, обеспечивают лучшую производительность, но ошибки в коде могут привести к сбою и потенциально повреждению базы данных. Большинство встроенных функций написано на C.
Кроме того, PostgreSQL позволяет загружать процедурные языки в базу данных через расширения. В PostgreSQL включены три языковых расширения для поддержки Perl , Tcl и Python . Для Python по умолчанию ( или ) используется прекращенный Python 2 , даже в PostgreSQL 14; Python 3 также поддерживается путем выбора языка ). Внешние проекты обеспечивают поддержку многих других языков, включая PL / Java , JavaScript (PL / V8), PL / Julia PL / R , PL / Ruby и другие.
plpythonuplpython2uplpython3u
Триггеры
Триггеры - это события, вызванные действием операторов языка обработки данных SQL (DML). Например, инструкция INSERT может активировать триггер, который проверяет, допустимы ли значения инструкции. Большинство триггеров активируются только операторами INSERT или UPDATE .
Триггеры полностью поддерживаются и могут быть прикреплены к таблицам. Триггеры могут быть для столбцов и условными, в том смысле, что триггеры UPDATE могут нацеливаться на определенные столбцы таблицы, а триггерам можно указать для выполнения при наборе условий, указанных в предложении WHERE триггера. Триггеры могут быть прикреплены к представлениям с помощью условия INSTEAD OF. Несколько триггеров запускаются в алфавитном порядке. Помимо вызова функций, написанных на родном PL / pgSQL, триггеры также могут вызывать функции, написанные на других языках, таких как PL / Python или PL / Perl.
Асинхронные уведомления
PostgreSQL предоставляет асинхронную систему обмена сообщениями, доступ к которой осуществляется с помощью команд NOTIFY, LISTEN и UNLISTEN. Сеанс может выдать команду NOTIFY вместе с указанным пользователем каналом и дополнительной полезной нагрузкой, чтобы отметить происходящее конкретное событие. Другие сеансы могут обнаруживать эти события с помощью команды LISTEN, которая может прослушивать определенный канал. Эта функция может использоваться для самых разных целей, например, для сообщения другим сеансам информации об обновлении таблицы или для обнаружения отдельными приложениями, когда было выполнено определенное действие. Такая система предотвращает необходимость непрерывного опроса приложениями, чтобы узнать, не изменилось ли что-нибудь, и сокращает ненужные накладные расходы. Уведомления являются полностью транзакционными, поскольку сообщения не отправляются до тех пор, пока транзакция, из которой они были отправлены, не зафиксирована. Это устраняет проблему отправки сообщений о выполняемом действии, которое затем откатывается.
Многие соединители для PostgreSQL обеспечивают поддержку этой системы уведомлений (включая libpq, JDBC, Npgsql, psycopg и node.js), поэтому ее могут использовать внешние приложения.
PostgreSQL может действовать как эффективный, постоянный сервер «pub / sub» или сервер заданий, объединив LISTEN с FOR UPDATE SKIP LOCKED.
Правила
Правила позволяют переписывать «дерево запросов» входящего запроса. «Правила перезаписи запросов» прикрепляются к таблице / классу и «перезаписывают» входящий DML (выбор, вставка, обновление и / или удаление) в один или несколько запросов, которые либо заменяют исходный оператор DML, либо выполняются в дополнение к нему. Повторная запись запроса происходит после синтаксического анализа оператора DML, но до планирования запроса.
Другие функции запросов
- Сделки
- Полнотекстовый поиск
- Просмотры
- Материализованные представления
- Обновляемые представления
- Рекурсивные представления
- Внутреннее, внешнее (полное, левое и правое) и перекрестные соединения
- Суб выбирает
- Коррелированные подзапросы
- Регулярные выражения
- общие табличные выражения и доступные для записи общие табличные выражения
- Зашифрованные соединения через Transport Layer Security (TLS); текущие версии не используют уязвимый SSL, даже с этой опцией конфигурации
- Домены
- Точки сохранения
- Двухфазная фиксация
- Техника хранения негабаритных атрибутов (TOAST) используется для прозрачного хранения больших атрибутов таблиц (таких как большие вложения MIME или XML-сообщения) в отдельной области с автоматическим сжатием.
- Встроенный SQL реализован с помощью препроцессора. Код SQL сначала пишется встроенным в код C. Затем код запускается через препроцессор ECPG, который заменяет SQL вызовами библиотеки кода. Затем код можно скомпилировать с помощью компилятора C. Встраивание работает также с C ++, но не распознает все конструкции C ++.
Модель параллелизма
Сервер PostgreSQL основан на процессах (а не на потоках) и использует один процесс операционной системы на сеанс базы данных. Операционная система автоматически распределяет несколько сеансов по всем доступным ЦП. Многие типы запросов также могут быть распараллелены между несколькими фоновыми рабочими процессами, используя преимущества нескольких процессоров или ядер. Клиентские приложения могут использовать потоки и создавать несколько подключений к базе данных из каждого потока.
Безопасность
PostgreSQL управляет своей внутренней безопасностью на ролевой основе. Роль обычно рассматривается как пользователь (роль, которая может входить в систему) или группа (роль, членами которой являются другие роли). Разрешения могут быть предоставлены или отозваны для любого объекта до уровня столбца, а также могут разрешить / запретить создание новых объектов на уровне базы данных, схемы или таблицы.
Функция SECURITY LABEL PostgreSQL (расширение стандартов SQL) обеспечивает дополнительную безопасность; со встроенным загружаемым модулем, который поддерживает обязательный контроль доступа (MAC) на основе меток на основе политики безопасности Linux с усиленной безопасностью (SELinux).
PostgreSQL изначально поддерживает большое количество внешних механизмов аутентификации, в том числе:
- Пароль: SCRAM-SHA-256 (начиная с PostgreSQL 10), MD5 или обычный текст
- Общий прикладной программный интерфейс служб безопасности (GSSAPI)
- Интерфейс поставщика поддержки безопасности (SSPI)
- Kerberos
- Идентификатор (сопоставляет имя пользователя O / S, предоставленное сервером идентификатора, с именем пользователя базы данных)
- Peer (сопоставляет имя локального пользователя с именем пользователя базы данных)
-
Облегченный протокол доступа к каталогам (LDAP)
- Active Directory (AD)
- РАДИУС
- Сертификат
- Подключаемый модуль аутентификации (PAM)
Методы GSSAPI, SSPI, Kerberos, однорангового узла, идентификатора и сертификата также могут использовать указанный файл «карты», в котором перечислены пользователи, соответствующие этой системе проверки подлинности, которым разрешено подключаться в качестве конкретного пользователя базы данных.
Эти методы указаны в файле конфигурации аутентификации на основе хоста кластера ( pg_hba.conf), который определяет, какие соединения разрешены. Это позволяет контролировать, какой пользователь может подключаться к какой базе данных, откуда они могут подключаться (IP-адрес, диапазон IP-адресов, доменный сокет), какая система аутентификации будет применяться, и должно ли соединение использовать безопасность транспортного уровня (TLS).
Соответствие стандартам
PostgreSQL заявляет о высоком, но не полном соответствии с последним стандартом SQL (для версии 13 "в сентябре 2020 года PostgreSQL соответствует по крайней мере 170 из 179 обязательных функций для соответствия SQL: 2016 Core", и никакие другие базы данных полностью не соответствуют ему. ). Единственным исключением является обработка идентификаторов без кавычек, таких как имена таблиц или столбцов. В PostgreSQL они внутри сворачиваются до символов нижнего регистра, тогда как в стандарте говорится, что идентификаторы без кавычек должны быть свёрнуты до верхнего регистра. Таким образом, Fooдолжно быть эквивалентно FOOне в fooсоответствии со стандартом.
Тесты и производительность
Было проведено множество неформальных исследований производительности PostgreSQL. Улучшения производительности, направленные на улучшение масштабируемости, в значительной степени начались с версии 8.1. Простые тесты между версией 8.0 и версией 8.4 показали, что последняя была более чем в 10 раз быстрее для рабочих нагрузок только для чтения и по крайней мере в 7,5 раз быстрее для рабочих нагрузок чтения и записи.
Первый эталонный тест, соответствующий отраслевым стандартам и подтвержденный коллегами, был завершен в июне 2007 года с использованием сервера приложений Sun Java System Application Server (проприетарная версия GlassFish ) 9.0 Platform Edition, сервера Sun Fire на базе UltraSPARC T1 и PostgreSQL 8.2. Этот результат 778.14 SPECjAppServer2004 JOPS @ Standard выгодно отличается от 874 JOPS @ Standard с Oracle 10 на с Itanium -На HP-UX системы.
В августе 2007 года Sun представила улучшенный результат теста SPECjAppServer2004 JOPS @ Standard, составивший 813,73 балла. С тестируемой системой по сниженной цене соотношение цена / производительность улучшилось с 84,98 долл. США / JOPS до 70,57 долл. США / JOPS.
Конфигурация PostgreSQL по умолчанию использует только небольшой объем выделенной памяти для критически важных для производительности целей, таких как кэширование блоков базы данных и сортировка. Это ограничение в первую очередь связано с тем, что более старые операционные системы требовали изменений ядра, чтобы разрешить выделение больших блоков разделяемой памяти . PostgreSQL.org предоставляет советы по основным рекомендуемым практикам производительности в вики .
В апреле 2012 года Роберт Хаас из EnterpriseDB продемонстрировал линейную масштабируемость ЦП PostgreSQL 9.2 с использованием сервера с 64 ядрами.
Matloob Khushi провел сравнительный анализ PostgreSQL 9.0 и MySQL 5.6.15 на предмет их способности обрабатывать геномные данные. В своем анализе производительности он обнаружил, что PostgreSQL извлекает перекрывающиеся области генома в восемь раз быстрее, чем MySQL, используя два набора данных по 80000 в каждом, формируя случайные участки ДНК человека. Вставка и загрузка данных в PostgreSQL также были лучше, хотя общие возможности поиска в обеих базах данных были почти одинаковыми.
Платформы
PostgreSQL доступен для следующих операционных систем: Linux (все последние дистрибутивы), 64-разрядные установщики x86 доступны и протестированы для macOS (OS X) версии 10.6 и новее - Windows (с установщиками доступны и протестированы для 64-разрядных Windows Server 2019 и 2016; некоторые старые версии PostgreSQL протестированы до Windows 2008 R2, в то время как для PostgreSQL версии 10 и старше доступен 32-разрядный установщик и протестирован до 32-разрядной версии Windows 2008 R1; компилируется, например, Visual Studio , версия 2013 до самая последняя версия 2019 г.) - FreeBSD , OpenBSD , NetBSD , AIX , HP-UX , Solaris и UnixWare ; и официально не протестированы: DragonFly BSD , BSD / OS , IRIX , OpenIndiana , OpenSolaris , OpenServer и Tru64 UNIX . Большинство других Unix-подобных систем также могут работать; самая современная вообще поддержка.
PostgreSQL работает на любой из следующих архитектур набора команд : x86 и x86-64 в Windows XP (или новее) и других операционных системах; они поддерживаются не в Windows: IA-64 Itanium (внешняя поддержка HP-UX), PowerPC , PowerPC 64, S / 390 , S / 390x , SPARC , SPARC 64, ARMv8 -A ( 64-бит ) и более ранние версии ARM ( 32-разрядная версия, включая более старые, такие как ARMv6 в Raspberry Pi ), MIPS , MIPSel и PA-RISC . Также было известно, что он работает на некоторых других платформах (хотя не тестировался годами, то есть для последних версий).
Администрирование базы данных
Интерфейсы с открытым исходным кодом и инструменты для администрирования PostgreSQL включают:
- psql
- Основным интерфейсом для PostgreSQL является программа
psqlкомандной строки , которую можно использовать для прямого ввода SQL-запросов или их выполнения из файла. Кроме того, psql предоставляет ряд мета-команд и различных функций, подобных оболочке, для облегчения написания сценариев и автоматизации широкого спектра задач; например, завершение имен объектов с помощью табуляции и синтаксиса SQL. - pgAdmin
- Пакет pgAdmin - это бесплатный инструмент администрирования с графическим пользовательским интерфейсом (GUI) с открытым исходным кодом для PostgreSQL, который поддерживается на многих компьютерных платформах. Программа доступна более чем на десятке языков. Первый прототип, названный pgManager, был написан для PostgreSQL 6.3.2 с 1998 года, а в последующие месяцы переписан и выпущен как pgAdmin под лицензией GNU General Public License (GPL). Второе воплощение (названное pgAdmin II) было полностью переписанным, впервые выпущенным 16 января 2002 года. Третья версия, pgAdmin III, первоначально была выпущена под лицензией Artistic License, а затем выпущена под той же лицензией, что и PostgreSQL. В отличие от предыдущих версий, написанных на Visual Basic , pgAdmin III написан на C ++ с использованием инфраструктуры wxWidgets, что позволяет ему работать в большинстве распространенных операционных систем. Инструмент запросов включает язык сценариев pgScript для поддержки задач администрирования и разработки. В декабре 2014 года Дэйв Пейдж, основатель проекта pgAdmin и основной разработчик, объявил, что с переходом к веб-моделям началась работа над pgAdmin 4 с целью облегчить развертывание в облаке. В 2016 году был выпущен pgAdmin 4. Бэкэнд pgAdmin 4 был написан на Python с использованием фреймворка Flask и Qt .
- phpPgAdmin
- phpPgAdmin - это веб-инструмент администрирования PostgreSQL, написанный на PHP и основанный на популярном интерфейсе phpMyAdmin, изначально написанном для администрирования MySQL .
- Студия PostgreSQL
- PostgreSQL Studio позволяет пользователям выполнять важные задачи разработки баз данных PostgreSQL с веб-консоли. PostgreSQL Studio позволяет пользователям работать с облачными базами данных без необходимости открывать брандмауэры.
- TeamPostgreSQL
- Управляемый AJAX / JavaScript веб-интерфейс для PostgreSQL. Позволяет просматривать, поддерживать и создавать данные и объекты базы данных через веб-браузер. Интерфейс предлагает редактор SQL с вкладками с автозаполнением, виджеты редактирования строк, навигацию по внешнему ключу между строками и таблицами, управление избранным для часто используемых сценариев, а также другие функции. Поддерживает SSH как для веб-интерфейса, так и для соединений с базой данных . Доступны установщики для Windows, Macintosh и Linux, а также простой кроссплатформенный архив, запускаемый из сценария.
- LibreOffice, OpenOffice.org
- LibreOffice и OpenOffice.org Base можно использовать в качестве интерфейса для PostgreSQL.
- pgBadger
- Анализатор журналов pgBadger PostgreSQL генерирует подробные отчеты из файла журнала PostgreSQL.
- pgDevOps
- pgDevOps - это набор веб-инструментов для установки и управления несколькими версиями PostgreSQL, расширений и компонентов сообщества, разработки SQL-запросов, мониторинга запущенных баз данных и поиска проблем с производительностью.
- Администратор
- Adminer - это простой веб-инструмент администрирования PostgreSQL и других, написанный на PHP.
- pgBackRest
- pgBackRest - это инструмент резервного копирования и восстановления для PostgreSQL, который обеспечивает поддержку полного, дифференциального и инкрементного резервного копирования.
- pgaudit
- pgaudit - это расширение PostgreSQL, которое обеспечивает подробное ведение журнала аудита сеанса и / или объекта с помощью стандартного средства ведения журнала, предоставляемого PostgreSQL.
- Wal-e
- Wal-e - это инструмент резервного копирования и восстановления для PostgreSQL, который обеспечивает поддержку физических (на основе WAL) резервных копий, написанных на Python.
Ряд компаний предлагают собственные инструменты для PostgreSQL. Часто они состоят из универсального ядра, адаптированного для различных конкретных продуктов баз данных. Эти инструменты в основном имеют общие функции администрирования с инструментами с открытым исходным кодом, но предлагают улучшения в моделировании данных , импорте, экспорте или отчетности.
Известные пользователи
Известные организации и продукты, использующие PostgreSQL в качестве основной базы данных, включают:
- В 2009 году сайт социальной сети Myspace использовал базу данных nCluster от Aster Data Systems для хранения данных, которая была построена на немодифицированном PostgreSQL.
- Geni.com использует PostgreSQL в качестве своей основной генеалогической базы данных.
- OpenStreetMap , совместный проект по созданию бесплатной редактируемой карты мира.
- Afilias , реестры доменов для .org , .info и других.
- Многопользовательские онлайн-игры Sony Online .
- BASF , торговая платформа для портала агробизнеса.
- Социальный новостной сайт Reddit .
- Приложение Skype VoIP, центральные бизнес- базы данных.
- Sun xVM , пакет Sun для виртуализации и автоматизации центров обработки данных.
- MusicBrainz , открытая музыкальная онлайн-энциклопедия.
- Международная космическая станция - для сбора телеметрических данных на орбите и скопировать его на землю.
- Социальная сеть MyYearbook .
- Instagram , мобильный сервис для обмена фотографиями.
- Disqus , онлайн-сервис для обсуждения и комментирования.
- TripAdvisor , туристический информационный сайт, содержащий в основном пользовательский контент.
- Яндекс , российская интернет-компания, перешла на сервис Яндекс.Почта с Oracle на Postgres.
- Amazon Redshift , часть AWS, системы столбчатой онлайн-аналитической обработки (OLAP), основанной на модификациях Postgres от ParAccel .
- Национальная служба погоды (NWS) Национального управления океанических и атмосферных исследований (NOAA) , интерактивная система подготовки прогнозов (IFPS), система, которая объединяет данные с метеорологических радаров NEXRAD , наземных и гидрологических систем для создания подробных локализованных моделей прогнозов.
- Национальная метеорологическая служба Соединенного Королевства , Met Office , начала замену Oracle на PostgreSQL в рамках стратегии по развертыванию большего количества технологий с открытым исходным кодом.
- WhitePages.com использовал Oracle и MySQL , но когда дело дошло до перемещения основных каталогов внутри компании, он обратился к PostgreSQL. Поскольку WhitePages.com необходимо объединять большие наборы данных из нескольких источников, способность PostgreSQL загружать и индексировать данные с высокой скоростью была ключом к его решению использовать PostgreSQL.
- FlightAware , сайт отслеживания рейсов.
- Grofers , онлайн-сервис доставки продуктов.
- The Guardian перешел с MongoDB на PostgreSQL в 2018 году.
Реализации сервисов
Некоторые известные производители предлагают PostgreSQL как программное обеспечение как услугу :
- Heroku , платформа в качестве поставщика услуг, поддерживает PostgreSQL с самого начала в 2007 году. Они предлагают дополнительные функции, такие как полный откат базы данных (возможность восстановления базы данных в любое заданное время), основанный на WAL-E, программное обеспечение с открытым исходным кодом, разработанное Heroku.
- В январе 2012 года EnterpriseDB выпустила облачную версию PostgreSQL и собственного проприетарного сервера Postgres Plus Advanced Server с автоматическим выделением ресурсов для аварийного переключения, репликации, балансировки нагрузки и масштабирования. Он работает на Amazon Web Services . С 2015 года Postgres Advanced Server предлагается как ApsaraDB для PPAS, реляционной базы данных в качестве услуги в Alibaba Cloud.
- VMware предлагает vFabric Postgres (также называемый vPostgres) для частных облаков на платформе VMware vSphere с мая 2012 года. Компания объявила об окончании доступности (EOA) продукта в 2014 году.
- В ноябре 2013 года Amazon Web Services объявила о добавлении PostgreSQL в свое предложение службы реляционных баз данных .
- В ноябре 2016 года Amazon Web Services объявила о добавлении совместимости с PostgreSQL к своим облачным управляемым базам данных Amazon Aurora .
- В мае 2017 года Microsoft Azure анонсировала базы данных Azure для PostgreSQL.
- В мае 2019 года Alibaba Cloud анонсировала PolarDB для PostgreSQL.
- Платформа Jelastic Multicloud как услуга обеспечивает поддержку PostgreSQL на основе контейнеров с 2011 года. Они предлагают автоматическую асинхронную репликацию PostgreSQL «главный-подчиненный», доступную на торговой площадке .
- В июне 2019 года IBM Cloud анонсировала IBM Cloud Hyper Protect DBaaS для PostgreSQL .
- В сентябре 2020 года Crunchy Data анонсировала Crunchy Bridge .
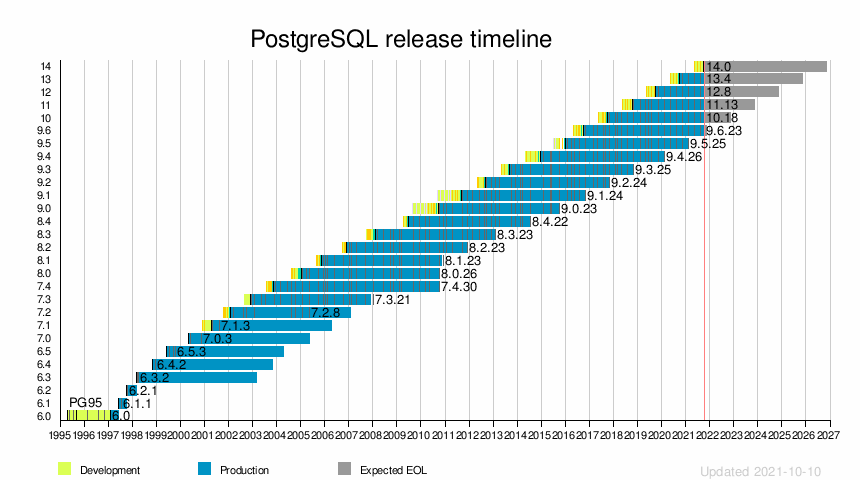
История выпуска
| Выпускать | Первый выпуск | Последняя дополнительная версия | Последний релиз | Конец жизни |
Вехи |
|---|---|---|---|---|---|
| 6.0 | 1997-01-29 | N / A | N / A | N / A | Первый официальный выпуск PostgreSQL, уникальные индексы, утилита pg_dumpall, идентификационная аутентификация |
| 6.1 | 1997-06-08 | 6.1.1 | 1997-07-22 | N / A | Многоколоночные индексы, последовательности, тип данных денег, GEQO (GEnetic Query Optimizer) |
| 6.2 | 1997-10-02 | 6.2.1 | 1997-10-17 | N / A | Интерфейс JDBC, триггеры, интерфейс программирования сервера, ограничения |
| 6.3 | 1998-03-01 | 6.3.2 | 1998-04-07 | 2003-03-01 | Возможность подвыбора SQL-92, PL / pgTCL |
| 6.4 | 1998-10-30 | 6.4.2 | 1998-12-20 | 2003-10-30 | ПРОСМОТРЫ (только для чтения) и ПРАВИЛА, PL / pgSQL |
| 6.5 | 1999-06-09 | 6.5.3 | 1999-10-13 | 2004-06-09 | MVCC , временные таблицы, дополнительная поддержка операторов SQL (CASE, INTERSECT и EXCEPT) |
| 7.0 | 2000-05-08 | 7.0.3 | 2000-11-11 | 2004-05-08 | Внешние ключи, синтаксис SQL-92 для объединений |
| 7.1 | 2001-04-13 | 7.1.3 | 2001-08-15 | 2006-04-13 | Журнал упреждающей записи, внешние соединения |
| 7.2 | 2002-02-04 | 7.2.8 | 2005-05-09 | 2007-02-04 | PL / Python, OID больше не требуется, интернационализация сообщений |
| 7.3 | 2002-11-27 | 7.3.21 | 2008-01-07 | 2007-11-27 | Схема, табличная функция, подготовленный запрос |
| 7,4 | 2003-11-17 | 7.4.30 | 2010-10-04 | 2010-10-01 | Оптимизация JOIN и функций хранилища данных |
| 8.0 | 2005-01-19 | 8.0.26 | 2010-10-04 | 2010-10-01 | Собственный сервер в Microsoft Windows , точки сохранения , табличные пространства , восстановление на определенный момент времени |
| 8.1 | 2005-11-08 | 8.1.23 | 2010-12-16 | 2010-11-08 | Оптимизация производительности, двухэтапная фиксация, разделение таблицы , сканирование битовой карты индекса, общая блокировка строк, роли |
| 8,2 | 2006-12-05 | 8.2.23 | 2011-12-05 | 2011-12-05 | Оптимизация производительности, построение онлайн-индексов, рекомендательные блокировки, горячее резервирование |
| 8,3 | 2008-02-04 | 8.3.23 | 2013-02-07 | 2013-02-07 | Heap-только кортежи, полнотекстовый поиск , SQL / XML , типы ENUM, UUID типы |
| 8,4 | 2009-07-01 | 8.4.22 | 2014-07-24 | 2014-07-24 | Оконные функции, разрешения на уровне столбцов, параллельное восстановление базы данных, сортировка для каждой базы данных, общие табличные выражения и рекурсивные запросы |
| 9.0 | 2010-09-20 | 9.0.23 | 2015-10-08 | 2015-10-08 | Встроенная двоичная потоковая репликация , горячий резерв , возможность обновления на месте, 64-битная Windows |
| 9.1 | 2011-09-12 | 9.1.24 | 2016-10-27 | 2016-10-27 | Синхронная репликация , сопоставление по столбцам , незарегистрированные таблицы, изоляция сериализуемых моментальных снимков , записываемые общие табличные выражения, интеграция с SELinux , расширения, сторонние таблицы |
| 9.2 | 2012-09-10 | 9.2.24 | 2017-11-09 | 2017-11-09 | Каскадная потоковая репликация, сканирование только индекса, встроенная поддержка JSON , улучшенное управление блокировками, типы диапазонов, инструмент pg_receivexlog, индексы GiST с разделением по пространству |
| 9,3 | 2013-09-09 | 9.3.25 | 2018-11-08 | 2018-11-08 | Пользовательские фоновые рабочие процессы, контрольные суммы данных, выделенные операторы JSON, LATERAL JOIN, более быстрый pg_dump, новый инструмент мониторинга сервера pg_isready, функции триггеров, функции просмотра, внешние таблицы с возможностью записи, материализованные представления , улучшения репликации |
| 9,4 | 2014-12-18 | 9.4.26 | 2020-02-13 | 2020-02-13 | Тип данных JSONB, оператор ALTER SYSTEM для изменения значений конфигурации, возможность обновления материализованных представлений без блокировки чтения, динамическая регистрация / запуск / остановка фоновых рабочих процессов, API логического декодирования, улучшения индекса GiN, поддержка огромных страниц Linux, перезагрузка кеша базы данных через pg_prewarm , повторно вводя Hstore в качестве предпочтительного типа столбца для данных в стиле документа. |
| 9,5 | 2016-01-07 | 9.5.25 | 2021-02-11 | 2021-02-11 | UPSERT, безопасность на уровне строк, TABLESAMPLE, CUBE / ROLLUP, GROUPING SETS и новый индекс BRIN |
| 9,6 | 2016-09-29 | 9.6.23 | 2021-08-12 | 2021-11-11 | Поддержка параллельных запросов, улучшения оболочки внешних данных PostgreSQL (FDW) с сортировкой / объединением, несколько синхронных резервных серверов, более быстрая очистка больших таблиц |
| 10 | 2017-10-05 | 10,18 | 2021-08-12 | 2022-11-10 | Логическая репликация, декларативное разбиение таблицы, улучшенный параллелизм запросов |
| 11 | 2018-10-18 | 11,13 | 2021-08-12 | 2023-11-09 | Повышенная надежность и производительность для секционирования, транзакции, поддерживаемые хранимыми процедурами, расширенные возможности параллелизма запросов, JIT-компиляция для выражений |
| 12 | 2019-10-03 | 12,8 | 2021-08-12 | 2024-11-14 | Улучшения производительности запросов и использования пространства; Поддержка выражений пути SQL / JSON; сгенерированные столбцы; улучшения интернационализации и аутентификации; новый подключаемый интерфейс для хранения таблиц. |
| 13 | 2020-09-24 | 13,4 | 2021-08-12 | 2025-11-13 | Экономия места и повышение производительности за счет исключения дублирования записей индекса B-дерева, повышение производительности запросов, использующих агрегаты или многораздельные таблицы, лучшее планирование запросов при использовании расширенной статистики, параллельная очистка индексов, инкрементная сортировка |
| 14 | 2021-09-30 | 14.0 | 2021-09-30 | 2026-11-12 | Добавлены стандартные предложения SQL SEARCH и CYCLE для общих табличных выражений, позволяющие добавлять DISTINCT в GROUP BY. |
Смотрите также
- Сравнение систем управления реляционными базами данных
- Масштабируемость базы данных
- Список баз данных, использующих MVCC
- LLVM (llvmjit - это JIT-движок, используемый PostgreSQL)
- Соответствие SQL
использованная литература
дальнейшее чтение
- Обе, Регина; Сюй, Лев (8 июля 2012 г.). PostgreSQL: готово и работает . О'Рейли . ISBN 978-1-4493-2633-3.
- Кросинг, Ханну; Ройбал, Кирк (15 июня 2013 г.). Программирование сервера PostgreSQL (второе изд.). Packt Publishing . ISBN 978-1-84951-698-3.
- Риггс, Саймон; Кросинг, Ханну (27 октября 2010 г.). Поваренная книга администратора PostgreSQL 9 (второе изд.). Packt Publishing . ISBN 978-1-84951-028-8.
- Смит, Грег (15 октября 2010 г.). PostgreSQL 9 Высокая производительность . Packt Publishing . ISBN 978-1-84951-030-1.
- Гилмор, У. Джейсон; Угощение, Роберт (27 февраля 2006 г.). Начиная с PHP и PostgreSQL 8: от новичка до профессионала . Апресс . п. 896. ISBN 1-59059-547-5. Архивировано из оригинала на 8 июля 2009 года . Проверено 28 апреля 2009 года .
- Дуглас, Корри (5 августа 2005 г.). PostgreSQL (второе изд.). Sams . п. 1032. ISBN 0-672-32756-2.
- Мэтью, Нил; Камни, Ричард (6 апреля 2005 г.). Начало баз данных с PostgreSQL (второе изд.). Апресс . п. 664. ISBN 1-59059-478-9. Архивировано из оригинала 9 апреля 2009 года . Проверено 28 апреля 2009 года .
- Уорсли, Джон С; Дрейк, Джошуа Д. (январь 2002 г.). Практичный PostgreSQL . O'Reilly Media . С. 636 . ISBN 1-56592-846-6.
внешние ссылки
-
Официальный веб-сайт

- PostgreSQL в компании Curlie
- PostgreSQL на GitHub